Transformation Pipeline
FLAIR-GG has a data transformation pipeline that begins with a Germplasm data provider exporting their data following one of the three Semantic Model's CSV templates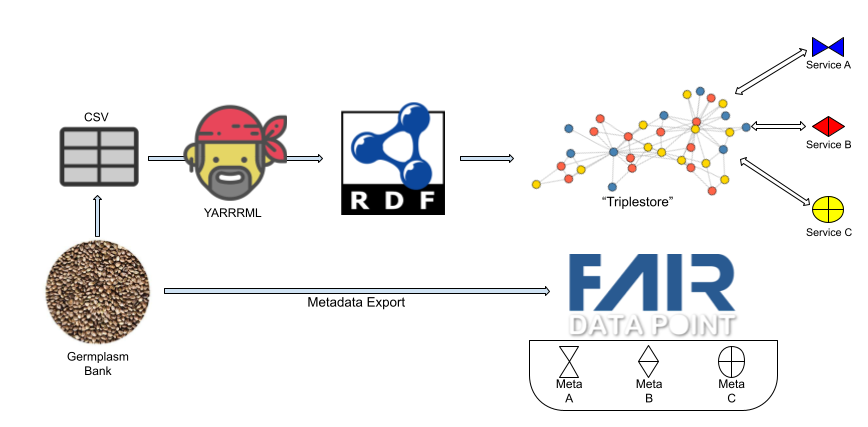
The upper workflow shows the data transformation pipeline that uses CSV as an intermediate representation between the native germplasm database, and the final FAIR data that appears in the Triplestore. Pre-configured and shared YARRRML templates are used to direct the transformation of the CSV into RDF, which is then published in the triplestore. Any interfaces (Service A/B/C) into the data are then pointed at this FAIR representation, rather than the database itself, enabling interoperability between non-coordinating germplasm banks.
The lower horizontal workflow shows the export of metadata describing the germplasm bank, and the nature of the data it holds, into a FAIR Data Point. This includes metadata describing any interfaces that might exist that allow exploration of the data itself (Meta A/B/C in the diagram).